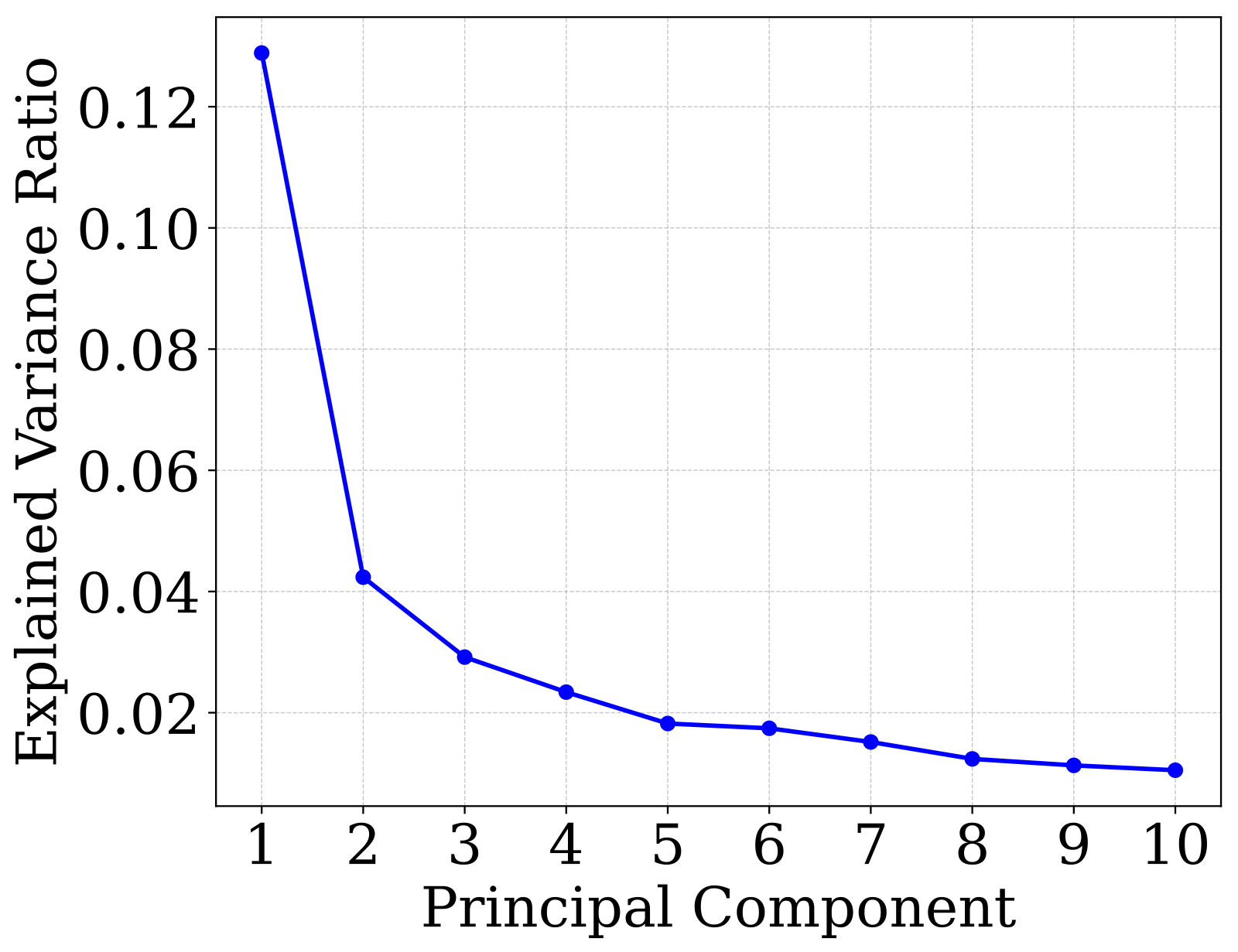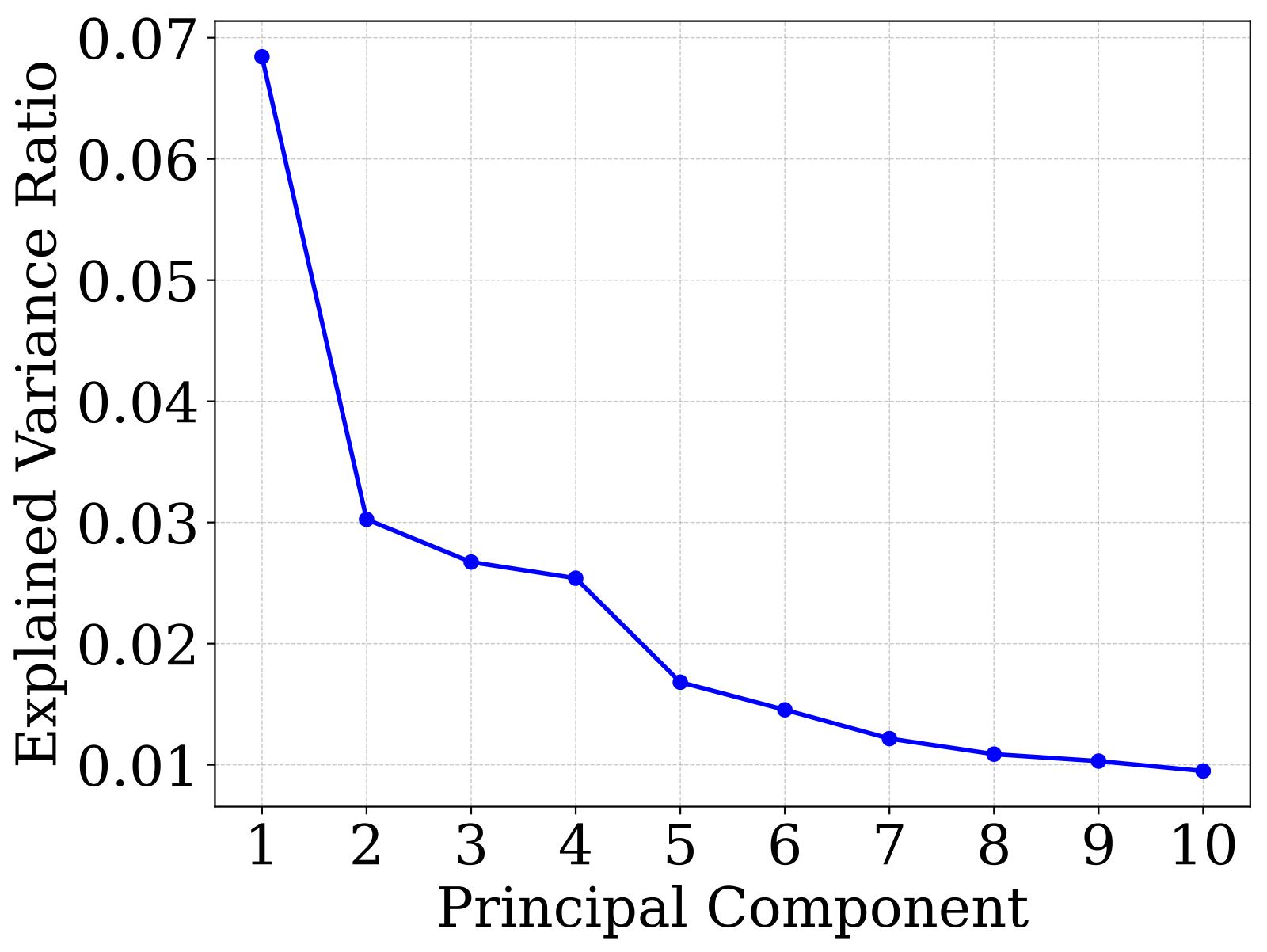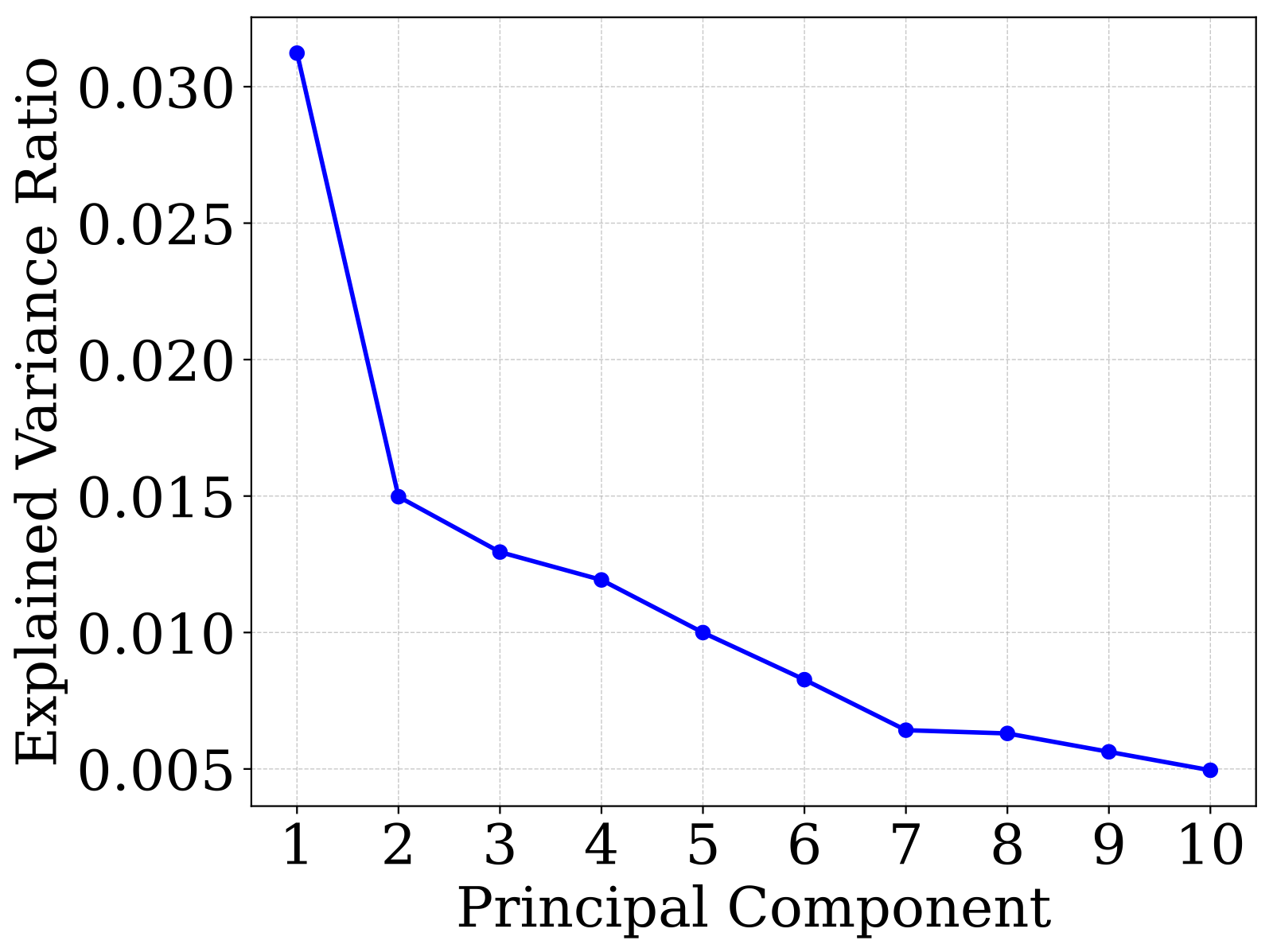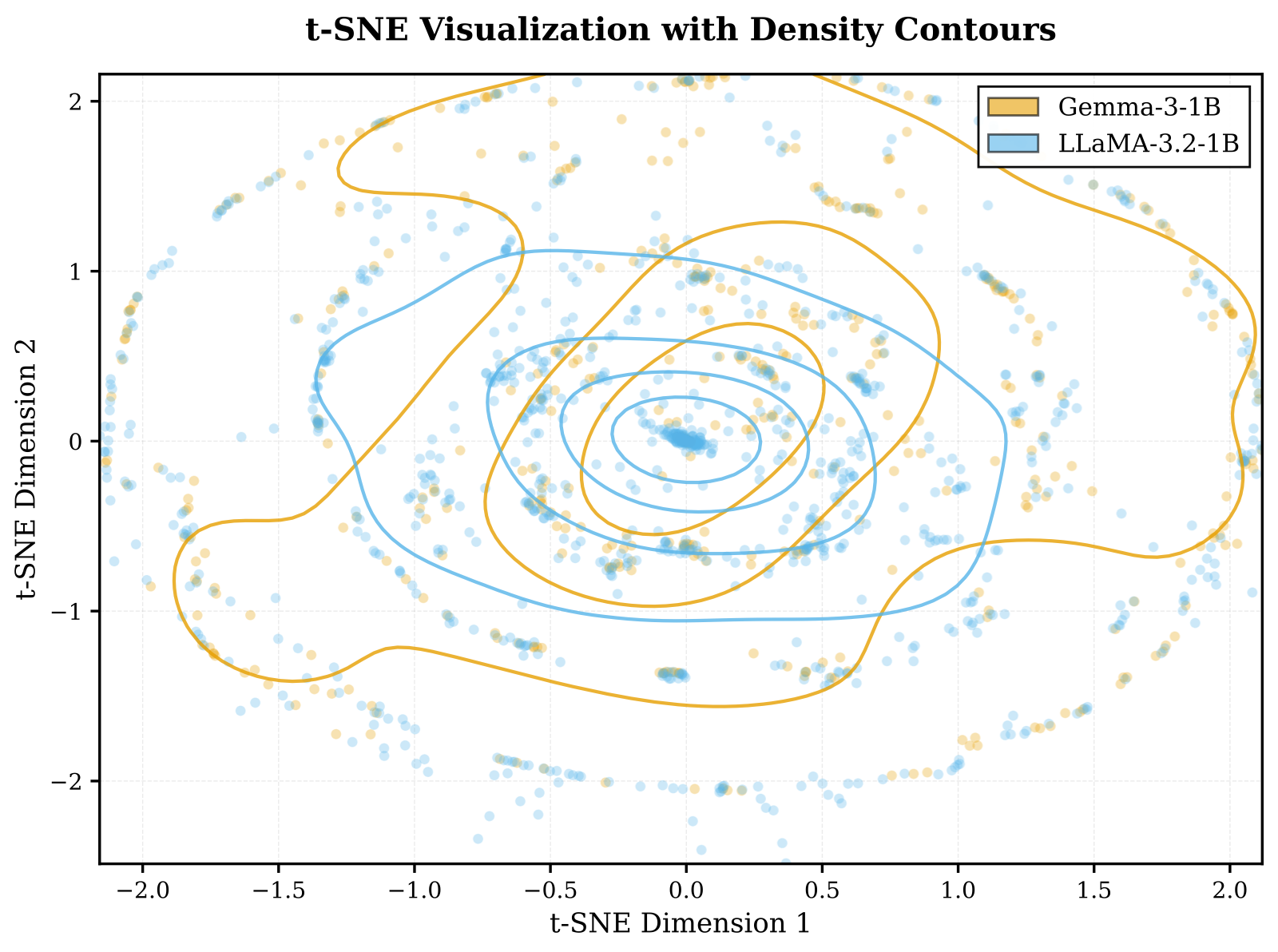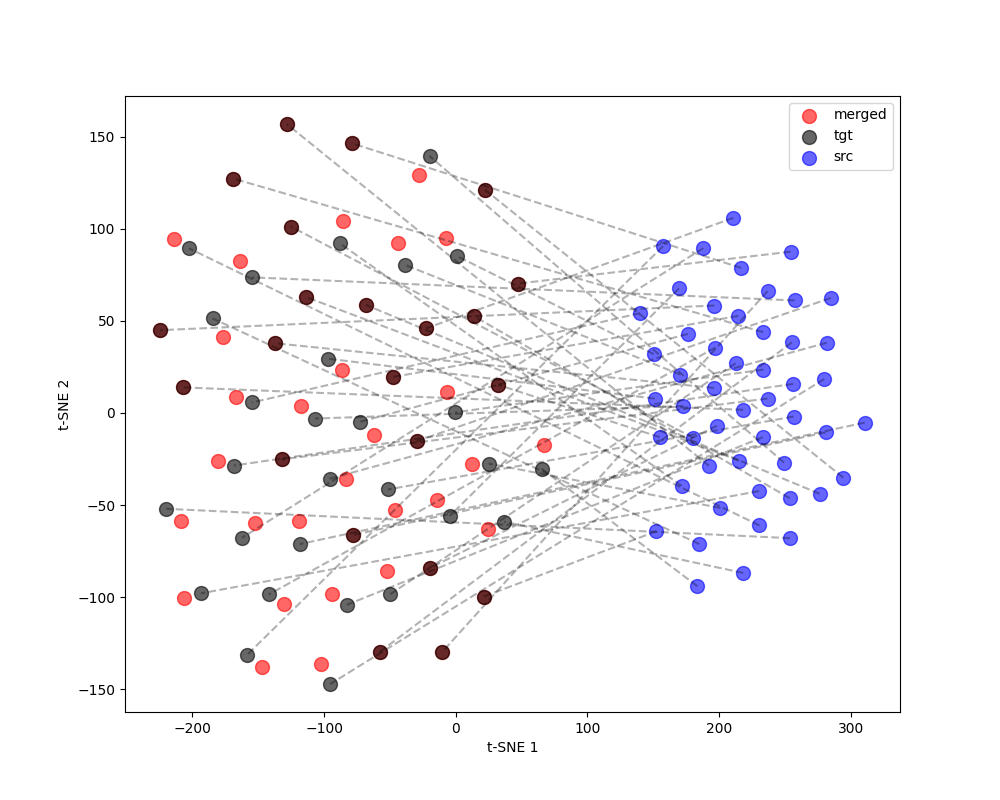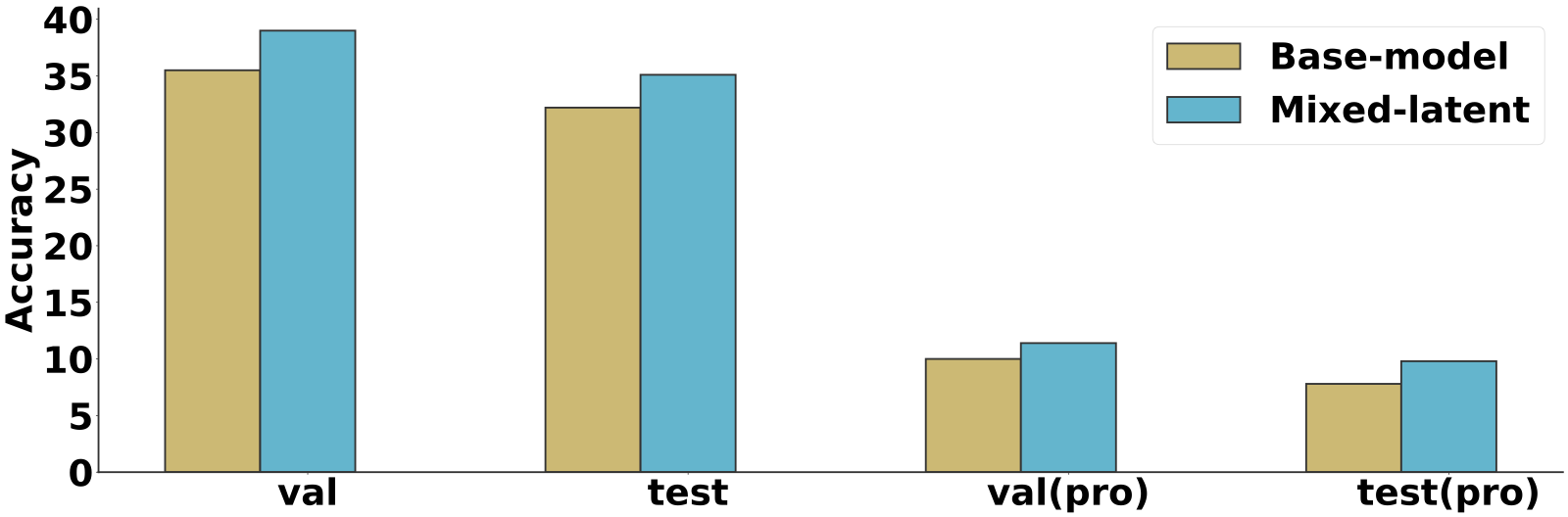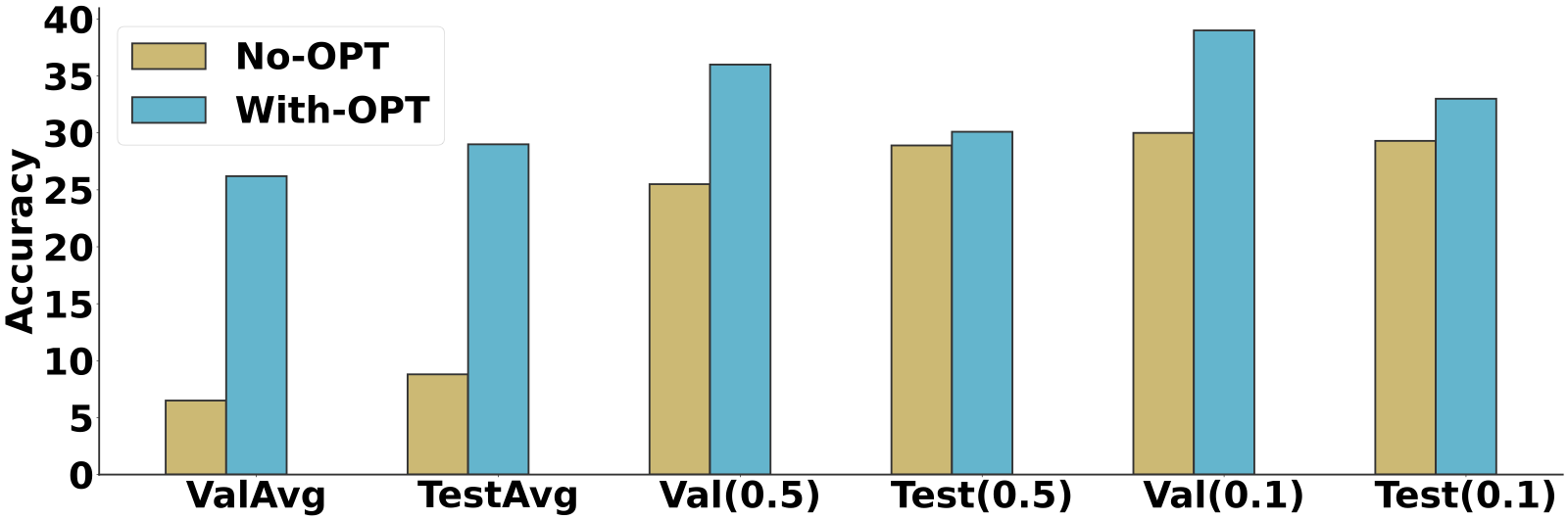
Width mismatch: WA ∈ ℝn×4096 vs. WB ∈ ℝn×2048 — element-wise averaging is undefined.
Depth mismatch: 26 layers vs. 36 layers — no natural 1-to-1 correspondence.
Family mismatch: Gemma and LLaMA have fundamentally different weight layouts.
All existing weight-space methods (Model Soup, SLERP, Task Arithmetic, TIES, DARE) require identical architectures.